In today’s multi-screen world we need to be able to get relevant
content to the customer, at the right time in their format and language of
choice. Life is no longer as simple as making PDF documents, we need to feed
consistent information to all our multi-channel publications
(web/mobile/print) and those of our partners. This blog post explains how NXP
is tackling these challenges.
At NXP, similar to many other large organizations, we have what you might
call a ‘brownfield’ information landscape. Data and content is
scattered and duplicated across numerous applications and databases leading to
inconsistent information, complex systems and inefficient processes. The
outcome is that people are unable to find what they are looking for, or find
conflicting information. Common approaches like Data Warehousing, Master Data
Management and Service-Oriented Architecture all tackle parts of the problem,
but none provide a total solution.
Our aim is to provide a single, up-to-date ‘canonical’ source of
information that is easy to use and that data consumers (be they human or
machine) can trust. By doing this we can make sure all our publications are
kept up-to-date with the minimum amount of fuss.
The answer we found was to take the best of the previously mentioned
approaches and combine with a liberal sprinkling of “Linked
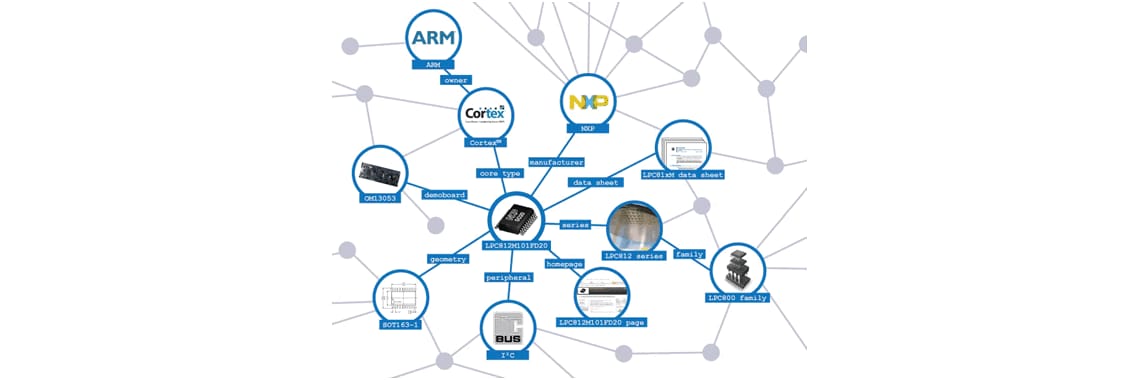
Data”. The result is a giant graph of data. Think of it like a social
network, but with things (products, places, technologies, applications,
documents, web pages) as well as people.
Linked Data… what’s that?
The idea of the Linked Data has been around for a while already, as Sir Tim
Berners-Lee put it “The Semantic Web
isn’t just about putting data on the web. It is about making links, so
that a person or machine can explore the web of data. With linked data, when
you have some of it, you can find other, related, data.” In the past
few years this approach has been used in publishing government data sets and
has been steadily gaining traction within media and enterprise sectors.
We have been eager to jump into this approach ourselves. For the the past few
years we have been making use of data dictionaries to ensure high-quality,
structured product data based on canonical property definitions. So far we
have mostly been using this data to reproduce existing publications like data
sheets and product web pages in a more efficient manner. However we always
felt “spoofing” these publications was not really showing off
the data to its full potential. So in the past year we have been looking at
new and innovative ways to publish our product data. When looking at Linked
Data and
RDF, we recognised an immediate affinity with our dictionary-based strategy.
For those readers unfamiliar with RDF and Linked Data, I will not go into
details here, rather advise you to read a
quick intro to RDF and the excellent
Linked Data Book.
Business drivers
The main business drivers for this have, so far, been mostly internal: how to
ensure product data is available across internal systems in an easy-to-use and
efficient manner. In many areas simple XML messages and other B2B standards
are applicable, but within a portfolio of over 20,000 products across a broad
variety of functions and technology it simply is not possible to describe the
complex properties of an electronic component with a handful of standard XML
elements. Also the tree-based XML DOM soon starts to become a limitation when
dealing with a highly-interlinked web of information. The answer (as it turns
out) is quite simple: think graph.
The benefits of the Linked Data approach are clear: we provide data consumers
a single, trustworthy, easy to use source of information about our products.
The Linked Data is the API. The benefit to our end-customer is that the
information published on our website, data sheets, selection guides and
partner websites is consistent and up-to-date.
Progress so far
Following the basic Linked Data principles we have assigned HTTP URIs as names
for things (resources) providing an unambiguous identifier. Next up we have
converted data from a variety of sources (XML, CSV, RDBMS) into RDF.
One of the key features of RDF is the ability to easily merge data about a
single resource from multiple sources into a single “supergraph”
providing a more complete description of the resource. By loading the RDF into
a graph database, it is possible to make an endpoint available which can be
queried using the
SPARQL query language. We are currently using
Dydra
as their cloud-based database-as-a-service model provides an easy entry route
to using RDF without requiring a steep learning curve (basically load your RDF
and you’re away), but there are plenty of other options like Apache
Jena and OpenRDF Sesame. This has made it very easy for us to answer to
complex questions requiring data from multiple sources, moreover we can stand
up APIs providing access to this data in minutes.
By using a
Linked Data Plaform such as
Graphity we can make our identifiers (HTTP URIs) dereferencable. In
layman’s terms when someone plugs the URI into a browser, we provide a
description of the resource in HTML.
Using content negotiation we are able to provide this data in one of the standard
machine-readable XML, JSON or Turtle formats. Graphity uses Java and XSLT 2.0
which our developers already have loads of experience with and provides
powerful mechanisms with which we will be able to develop some great web apps.
Next steps
For now, as mentioned above, the main drivers are internal. However, where
possible/relevant, we are planning to make data publicly accessible under an
open license. We’re currently experimenting with making test data
available via a beta public SPARQL endpoint and linked data app
as we develop it. These are by no means finished, but represent our current
progress.
Over the coming months we will be making more and more data available as
linked data and gradually reworking our existing publications to use the new
data source. Alongside this we are confident that development of new and
exciting ways to explore and visualize information will be made much easier by
having a great easy-to-use source of information. We already have some cool
ideas for faceted search type interfaces that we will be launching in beta as
soon as we can. Keep your eyes peeled!
Feedback
We’d really appreciate your input and thoughts. If you have any cool
ideas about how you might want to use our data, or would like to see more of
our data published using other vocabularies, we’d love to hear from
you. Also we’d be very interested to hear from anyone else in the
electronics industry interested in making product data more open and aligned.
Please leave a comment below or tweet us at
@nxpdata.