As society talks more about artificial intelligence and the role it will play in our future, a key
question that NXP is looking at is how to make AI and ML safe in terms of our development
processes?
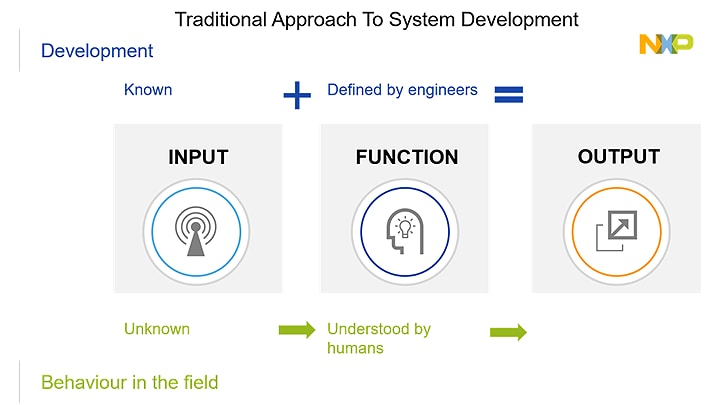
At NXP, we develop a function for our hardware from the formal requirements given by our customer.
For these requirements to work, we start by listing some known inputs – these are the use cases. A
use case could be the location a radar sensor has in the car (front-facing, corner), the operating
voltage of an electric vehicle’s battery or the number of screens in a car’s cockpit. We can then
define the design and verify that the function behaves as we are expecting it to—not only in
simulation, but also in the field. In the field we are incapable of controlling what the function
will actually have as inputs, and we therefore design our functions to be as robust as possible
within the chosen use-cases.
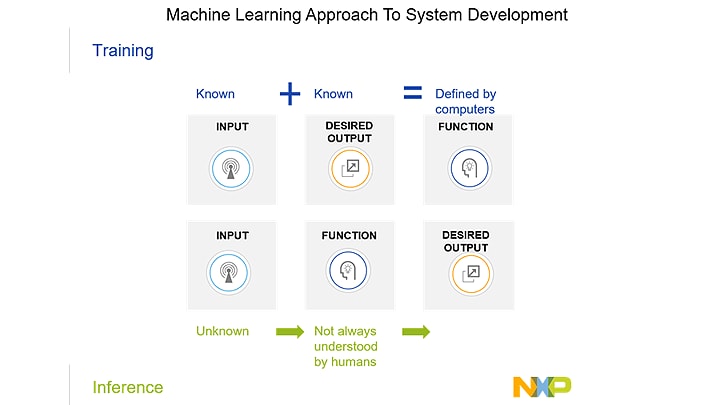
But when we talk about AI this changes a little. We still define the use cases, but now we assign
to each a clear, defined, non-ambiguous output. This is given to the computer which then defines
the function. This process of learning from examples can be referred to as training. We teach the
computer to deliver the response we need.
Once the machine is trained on the use cases, we transfer this knowledge to our devices where it
applies them to the field with unseen data. This is called inference. The key difference between
this process and the non-AI process, is that engineers may not necessarily understand the function
itself as we did in the past.
This means that we need to evaluate and adjust the behaviour until the outputs match our original
expectations. This adjustment process takes place in the cloud for high-compute devices, not at
the edge.
What Is Safe AI/ML? Why Do We Need It?
AI and ML will make their way into automotive safety functions and it will be necessary to make
sure that there are no violations of the safety goals. If you think about AI and ML in the context
of the automotive industry, the question for a car OEM is understanding the level of risk and
probable harm to humans from a given function. So, functions are defined to avoid systematic
failures and also to reduce random failures. We handle these requirements with our safety
management process and our safety architectures that allow device monitoring in human-managed
development.
However, just following our existing development process would not be enough because training and
inference are inherently different. We therefore need to define different problem statements. To
start with, we need to understand if the training data is free from systematic faults. We also
need to know how the AI model is created. Does it create unwanted bias that may lead to systematic
faults? Finally, during inference, is the execution of the model free from random faults?
For a piece of this, ML assurance comes into play. ML assurance is concerned with the
completeness, correctness and coherence of the training and evaluation steps. It covers all of the
top level safety processes plus data management. This is to make sure that the data being used is
correct, complete and has no bias.
At the inference level, safety mechanisms ensure the integrity of the hardware. These can be any
form of hardware core. The classic safety mechanisms with ECC/parity, lockstep and flow monitor
features are enhanced by safety wrappers to run additional checks on the data and measure the
safety performance statistically.

At NXP, a white paper on the
morals of algorithms looks at how NXP views the integrity of AI development and the safety, security and
transparency of reliable AI. We have dedicated software called
Auto eIQ® to help developers evaluate, optimise and deploy their trained models into our targets.
This helps us to continue making the models more robust.
Explore more on safety at
nxp.com/functionalsafety.




