Application Note (5)
-
i.MX 8M Plus NPU Warmup Time[AN12964]
Fact Sheet (1)
-
eIQ Software Fact Sheet[EIQ-FS]
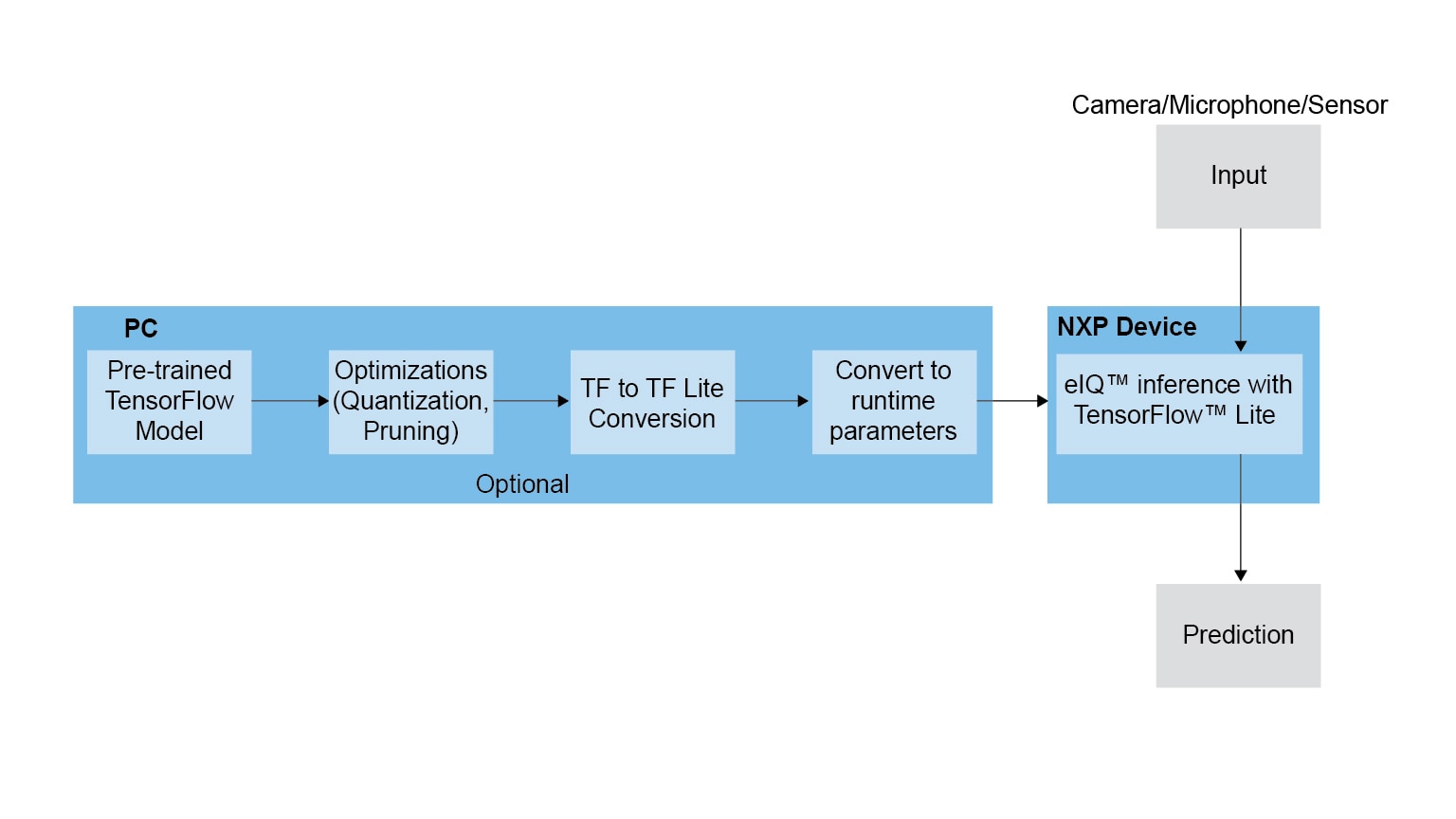
Integrated into NXP's Yocto development environment, eIQ software delivers TensorFlow Lite for NXP’s MPU platforms. Developed by Google to provide reduced implementations of TensorFlow (TF) models, TF Lite uses many techniques for achieving low latency such as pre-fused activations and quantized kernels that allow smaller and (potentially) faster models. Furthermore, like TensorFlow, TF Lite utilizes the Eigen library to accelerate matrix and vector arithmetic.
TF Lite defines a model file format, based on FlatBuffers. Unlike TF’s protocol buffers, FlatBuffers have a smaller memory footprint allowing better use of cache lines, leading to faster execution on NXP devices. TF Lite supports a subset of TF neural network operations, and also supports recurrent neural networks (RNNs) and long short-term memory (LSTM) network architectures.
2 downloads
Note: For better experience, software downloads are recommended on desktop.
Quick reference to our documentation types
6 documents
Compact List
1-5 of 6 hardware offerings



Additional hardware available. View our featured partner solutions.


Quick reference to our software types.
Note: For better experience, software downloads are recommended on desktop.
To get further assistance directly from NXP, please see our Engineering Services.
1 engineering service
To find a complete list of our partners that support this software, please see our Partner Marketplace.



















