I recently got into a discussion of which graphics card to pair with
LX2160A Block Diagram
processor. You can imagine how odd that felt. Like most other Layerscape processors, the LX2160A
processor targets headless embedded systems. It's not for computers, with their brawny CPUs and
slick user interfaces. True, it scores highly on general benchmarks, but its distinguishing
attributes are prodigious network acceleration and I/O performance. It's made for designs like
wireless transport cards and industrial controllers. Why hook up an LX2 chip to a GPU?
The answer is that LX2 is strong enough for a computer but made for demanding embedded
applications. The LX2 excels at general-purpose computation by dint of its 16 CPUs. Licensed from
Arm®, these Cortex®-A72 CPUs are used in other Layerscape processors
and other companies' ASICs. The latter include Tesla's "FSD computer", which has 12 of these CPUs
and Amazon Web Services's Graviton, which has 16 like the LX2. Our analysis shows the 16-core LX2
performing comparably to a 16-thread/8-core processor from a competing architecture typically
targeted at PCs and servers.
Applications demanding this kind of performance span a wide gamut. Some are data-plane functions
in the types of communication equipment that Layerscape and its Power Architecture®
predecessors have long targeted: transport cards in base stations, smart NICs for data-center
servers and Layer-2/Layer-3 accelerators for routers. These applications benefit from the LX2's
multitude of cores and the connectivity and crypto acceleration built into every Layerscape
processor.
Building a demanding embedded computing product?. Explore all the
LX2160A
can deliver.
NXP also has long targeted functions within communication equipment that benefits especially from
high single-thread performance. Here, too, LX2 shines-but in this case for its speedy CPUs that
carve through layers of software. Network function virtualization (NFV), for example, encapsulates
software inside a virtual machine that previously ran on standalone physical hardware. Although
virtualization originated with servers and workstations, it operates efficiently on NXP processors
thanks to the virtualization capabilities of our CPU cores and SoC chassis that we have been
designing in since the QorIQ P Series in 2008.
Various factors, nonetheless, conspire to absorb CPU cycles in typical NFV systems. The old
physical systems were purpose-built hardware with lean system software. Virtualized network
functions (VNFs), however, execute on general-purpose, computer-like hardware and system software,
which is intrinsically less efficient. These platforms, moreover, host multiple VNFs that
communicate with each other via virtual switches-Ethernet switches implemented in software.
Libraries such as the Data Plane Development Kit (DPDK) mitigate operating-system overhead but
rely on speedy cores to run tasks to completion. The LX2 has the requisite cores and NXP invests
in optimizing networking and virtualization software, such as DPDK and the Linux Kernel Virtual
Machine (KVM). NXP also invests in containerization, an alternative to virtualization with lower
overhead.
The most important software, however, is Linux. Yes, NXP still collaborates with embedded OS
specialists, such as Wind River. For customers wanting an open-source embedded experience, NXP
offers a Yocto embedded Linux development environment. However, many developers, especially, but
not exclusively, those with an IT background, prefer an environment like that on their computers.
A popular choice is NXP's Layerscape Development Kit (LSDK). It is a reference integration, an
example of how a customer can meld numerous components into a system image or personalized Linux
distribution.
To construct the LSDK, NXP starts by modifying numerous open-source boot loaders, kernels,
libraries and tools to work with a particular device, such as LX2. We submit these modifications
as patches to the associated open-source projects. Once upstreamed, the LSDK components are
available from public repositories, such as kernel.org and GitHub. NXP keeps these patches
updated, periodically releasing new versions and supporting two recent long-term-support (LTS)
kernels. Developers can select the components they need for their own integration. No massive ISO
file or tarball must be downloaded.
The LSDK reference integration conveniently includes a user land—the files and folder
hierarchy—derived from the popular Ubuntu distribution. This provides the developer a familiar
operating environment. Importantly, it also provides easy access to a vast library of binary
software. These applications run without a hitch because LX2 and other Layerscape processors use
standard Arm cores, maximizing compatibility. Other popular distributions also support 64-bit Arm
processors and developers building their own distribution with LSDK can adapt these user lands
instead of the Ubuntu example we provide. Figure 1 is a screenshot of a Linux desktop on LX2.
Figure 1. Screenshot of a Linux Desktop Running on the Layerscape LX2160A Processor
The performance and software ecosystem of LX2 is pulling it into markets beyond communication.
High-end assisted driving automation systems (ADAS) have often thrown server hardware at the
problem of integrating the information extracted from cameras, lidar and other sensors by
artificial intelligence (AI) hardware. Such hardware is bulky, expensive and hot. Offering
comparable performance and better integration and coming from a company with a track record of
meeting automakers' demands for supply longevity, safety and tolerance of harsh environments, LX2
is an appealing alternative. We're engaged with ADAS and self-driving efforts with major companies
worldwide. Similarly, customers are using LX2 in industrial machine vision, aerospace and
numerically controlled cutting machines.
Even within communication, LX2 can address workloads heretofore not run on a general-purpose
processor. For example, 5G cellular standards allow for various functional splits, including
implementing upper PHY functions in a system called a distributed unit (DU) instead of the channel
card of a traditional macro base station. These functions, which include channel coding, bit
manipulation, channel estimation, equalization and precoding, can run in software on a
general-purpose processor. That processor, however, must be able to crunch a lot of data. Our
analysis shows that the LX2 is up to the task.
For similar reasons, the LX2 is even finding its way into the datacenter, the stronghold of the
ultimate compute device, the 200W+ server chip. The LX2 doesn’t replace the server, but
complements it, by sitting on a network interface card plugged into the server. The LX2 offloads
networking tasks from those expensive and power-consumptive server cores. One example is this FPGA
+ LX2 NIC combination developed by Xilinx.

Datacenter equipment
To understand how LX2 delivers such competitive performance, let's look under the hood at some of
the blocks that contribute to its performance on general computational workloads. It has two
ECC-protected 64-bit interfaces to DDR4 memory, as the block diagram in Figure 2 shows. Although
this is fewer than server processors have, the LX2 operates its DDR4 interfaces at up to 3200
GT/s. This is about 50% faster than other processors on the market. The result is a balance of
good memory throughput and the lower cost associated with fewer wide DDR ports.
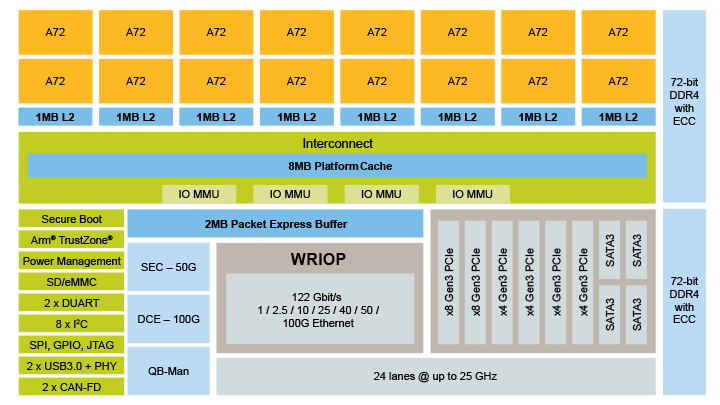
Figure 2. LX2160A Processor Block Diagram
Backing this up is 8MB of platform cache which buffers off-chip memory from accesses by CPU cores,
network accelerators and I/O controllers. A 2MB packet express buffer is also on-chip to minimize
DRAM access by the integrated Ethernet switch. Next to each pair of CPUs is 1MB of Level 2 cache.
This is the same amount per core as Graviton, which has no L3 cache and greater than many compute
processors. Being quicker to access than off-chip memory, caches are essential to feeding
instructions and data to CPUs.
As noted above, the LX2 uses Arm Cortex-A72 CPUs. They're among the company's "big" A-series
cores. Some Layerscape use the "little" Arm Cortex-A53 CPUs. The two are compatible, implementing
the same version of Arm's 64-bit instruction set. At the same clock rate, the A72 is about twice
as fast. It can decode three instructions per cycle and can execute them out of order in one of
eight pipelines. The A53 decodes and executes only two instructions at a time and does so to
reduce power and cost. The performance-oriented A72 also has faster floating-point units and wider
Neon SIMD execution units, enhancing its ability to carve up math-intensive computational
workloads, such as upper PHY functions in a wireless DU. Each of the A72's two Neon units can
compute two complex 16-bit multiply-accumulate operations per cycle.
In summary, the NXP Layerscape LX2160A processor excels at computing. We had a lead with a
customer looking to replace a PC processor in their embedded system. They wanted comparable
performance and didn't want to give up their software ecosystem. The LX2 fit the bill. An engineer
had a standard GPU card lying around and plugged it into a system's PCIe slot. Thanks to the
open-source community and LSDK, software installation was also a snap. Designed for the
environmental challenges of embedded systems and optimized for communications applications, the
LX2 is also shines at computational workloads. Perhaps NXP has found its new advertising slogan:
Strong enough for computing but made to be embedded.
For more information regarding the product and the related products, please visit
LX2160A




