It’s been a while since my last post (Mining sensor data, Part 4) back in April. We have had several training sessions on the topic of
sensor data analytics that roughly paralleled this blog series (see references at the end of this
article). We also spent a lot of time at our Technology Forum on the
Tech Lab floor running demos, one of which is shown in the video below.
I like this one because it’s a great example of some of the techniques
outlined in the earlier posts of this series.
What you see in the video is a commercial RV water pump plumbed to create a
small re-circulating water system. The RV pump is designed to turn on when
you open the sink faucet in your recreational vehicle. The red valve to
the right plays the roll of that faucet valve. There’s another
valve (not visible in the preview above) to the left, which can be used to block
the pump’s input – this would be an abnormal condition for the
pump. We used the small board shown attached to the pipe to measure
vibrations when the pump was off, operating properly, input blocked or input
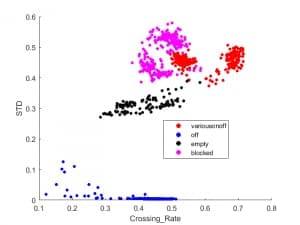
reservoir empty. That data is shown in the figure below. The X/Y/Z
values from the onboard accelerometer were used to compute vector magnitude vs
time. Then we took the standard deviation of the vector magnitude as one
“feature”, and the “zero crossing rate” as the
other. There was nice clean separation between the off state and others,
but a bit of overlap between the normal on state and two error states.
With more time and study, I hope to tweak the setup and/or analysis to get
better separation – but for a proof of concept demo, this gets the job
done.
Pump data collected at our Technology Forum
I took a lot of data on this setup, in a number of different environments
leading up to our Technology Forum. I’ve seen these clusters
move around. Sometimes the “empty” and
“blocked” clusters are difficult to distinguish. So
for the purposes of machine learning, I merged them into one common
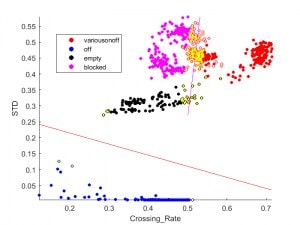
“error class”. I then computed a support vector machine
based on those collapsed sets.
SVM hyperplanes and support vectors
The figure above shows computed SVM hyperplanes, as well as the support
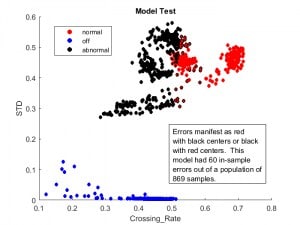
vectors (highlighted samples) used to compute them. The figure below
shows the in-sample errors of that SVM. Click on any of the three
figures to see an expanded view.
In-sample errors for the computed model
Once the SVM was computed in Matlab®, we exported the model as a
C-language function which was then inserted into a 2nd embedded program
designed to run on the same board used for the initial data logging. We
added a small “debounce” function to add some stability in the
transition regions, and then used the output of that to control the colors of
the LED on the board. We also interfaced with a second board which
offered wireless access to a
Thread-based network
for home automation. Every time the pump changed state, events were sent
out to various displays scattered around the Technology Forum flow.
Way cool!
At the end of
Part 4 of this series, I listed a bunch of warnings/lessons learned. I saw many of those
manifest themselves in this experiment as well. For instance, our first
pump was broken during shipment from Phoenix to Austin for our Technology
Forum. So we had to swap in the backup pump before the event. Over
the course of three days at our event, we could tell that the data clusters
moved as the new pump got “broken in”. I think this is
normal and to be expected. It again highlights the need to collect
enough data to guarantee that your “in-sample” probability
distributions are a reasonable approximation of your infinitely
large “out-of-sample” distributions.
This particular demo got a lot of interest from attendees, and I want to
personally thank those who visited the booth and then took up my invitation to
join an afternoon class on the topic. Most of those who attended then
stayed an extra 30 minutes past the formal end of the course to ask questions
and get a peek at our Matlab code. We only wrapped up when we got booted
out of the room for the next class! The whole event reinforced my belief
that we are seeing the birth of a new trend which utilizes sensor data
analytics to create new applications and create new value propositions for old
ones.
Mike Stanley develops advanced algorithms and applications for
MCUs and sensors, including sensor fusion and sensor data
analytics. He is a founding member of the MEMS Industry Group's
Accelerated Innovation Community and a contributor to the IEEE
Standard for Sensor Performance Parameter Definitions (IEEE
2700-2014). He is co-author of a chapter on intelligent sensors
in "Measurement, Instrumentation, and Sensors Handbook" (volume
two), and speaks on sensor topics. When the Arizona temperature
drops below 100 degrees, you'll find Mike flying his F450
quadcopter . Follow him @SensorFusion.