The world of machine learning, and more specifically deep learning, is a
rapidly growing field. It’s growing in the sense of how quickly the
market is expanding, especially as deep learning moves to the edge. In my
microcosm at NXP, I see the deep learning customer base increasing
dramatically, as more and more engineers build applications that include some
form of vision- or voice-based machine learning technology. The number of deep
learning frameworks, tools and other capabilities that allow developers to
build and deploy neural network models are also expanding.
One example of such a tool is the Glow neural network (NN) model compiler.
Aligned with the proliferation of deep learning frameworks such as PyTorch, NN
compilers provide optimizations to accelerate inferencing on a range of
hardware platforms. In May 2018, Facebook introduced Glow (the graph lowering
compiler) as an open source community project and it has evolved significantly
over the last two years thanks to the efforts of more than 130 worldwide
contributors.
Recently, we rolled out our official support for this Glow compiler and
we’re very excited about the performance and memory benefits
it’s delivering for our devices. We have tightly integrated Glow into
our MCUXpresso SDK, which packages the Glow compiler and quantization tools
into an easy-to-use installer along with detailed documentation and labs to
get running quickly with your own models.
Glow Flexible Functionality
As an NN compiler, Glow takes in a computation graph and generates optimized
machine code over two phases. In the first phase, it optimizes the operators
and layers of the model using standard compiler techniques such as kernel
fusion, lowering of complex operations to simple kernels and transpose
elimination. In the second, or backend phase of the model compilation, the
Glow compiler uses LLVM modules to enable target-specific optimizations. Glow
supports ahead of time (AOT) compilation, where compilation is performed
offline to generate an object file (called a Glow bundle) which is later
linked with the user’s application code. When this object file is
generated, all unnecessary overhead is eliminated, reducing the number of
computations as well as the memory overhead. This is ideal for deploying on
memory-constrained and low-cost microcontrollers.
Target-Specific Optimizations
While any device in our i.MX RT series will run a Glow compiled model, we
started our testing on the i.MX RT1060 MCU because we also have TensorFlow™
running on this device, and it allowed us to have a direct performance
comparison. We also started with the i.MX RT685 MCU because this is a new
device and the only one in our i.MX RT series with a DSP optimized for
processing neural network operators. The i.MX RT1060 MCU contains a 600 MHz
Arm® Cortex®-M7 and 1MB of SRAM. The i.MX
RT685 MCU contains a 600 MHz Cadence® Tensilica®
HiFi 4 DSP core paired with a 300 MHz Cortex-M33 core and 4.5 MB of on-chip
SRAM.
The standard version of Glow from GitHub is device agnostic; it can compile
for basic architectures of interest. For example, for cross-compiling a bundle
for the Arm Cortex-M7 core, use the command line –target=arm -mcpu=cortex-m7. However, as I mentioned, Glow’s LLVM backend support can
cross-compile bundles for different target architectures. NXP has taken
advantage of this by using Arm CMSIS-NN to leverage the full capability of the
Cortex-M7 as well as the memory subsystem of the i.MX RT1060 device. CMSIS-NN
is an Arm-developed library supporting Arm Cortex-M0, -M3, -M4, -M7 and -M33
cores and it implements standard NN operations like convolution, fully
connected, pooling and activation. Simply use the compilation flag -use-cmsis
when building quantized bundles, and the performance will increase
significantly above the standard compilation. For example, as measured by NXP
on a CIFAR-10 model, performance increases by almost 2x, when using the
CMSIS-NN library to accelerate NN operations.
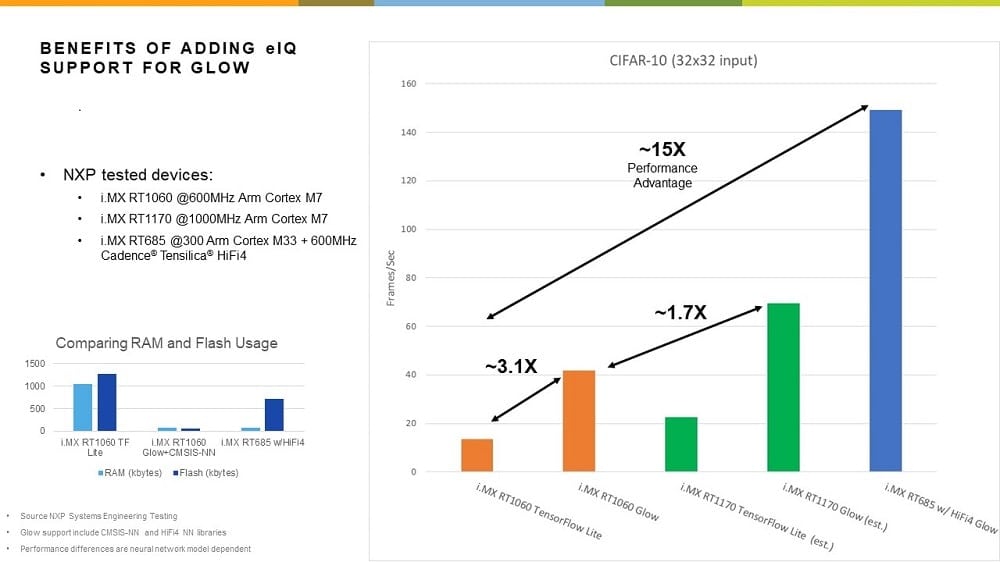
The HiFi 4 DSP core on the i.MX RT685 device is also capable of accelerating a
wide range of NN operators when used with Cadence’s NN library (NNLib)
as another LLVM backend for Glow. NN Lib is like CMSIS-NN, except it provides
a much more comprehensive set of hand-tuned operators optimized for the HiFi 4
DSP. For the same CIFAR-10 example, this DSP delivers a 25x performance
increase compared to the Glow standard implementation.
PyTorch for Embedded Systems
PyTorch can directly export models into the ONNX format for use by Glow.
Alternatively, since many well-known models were created in other formats
(e.g. TensorFlow), there are also open source model conversion tools to
convert them to the ONNX format. The most used tools for format conversion are
MMDNN, a set of tools supported by Microsoft® to help users
inter-operate among different deep learning frameworks and
tf2onnx
to convert TensorFlow models to ONNX. Furthermore, NXP has upstreamed to the
Glow community a support feature to bring TensorFlow Lite models in directly
to Glow. More recently, Glow can be directly accessed through PyTorch,
allowing users to build and compile their models in the same development
environment, thereby eliminating steps and simplifying the compilation
process.
However, because of its broad use in datacenters by companies such as
Facebook, people have questioned PyTorch’s ability to serve as a
framework for embedded MCUs. With Glow becoming directly accessible from
PyTorch, is there reason to be concerned that ’PyTorch, and hence Glow,
is not targeted at MCUs?’ The short answer is ‘no’,
especially given the AOT implementation of Glow.
To explain this further, it would be a valid impression that PyTorch itself
isn’t targeted towards MCUs. It’s a community project and no one
has stepped up yet to develop and maintain this approach. For obvious reasons,
Facebook does not use PyTorch on MCUs, but the embedded community is welcome
to contribute and add the end-to-end support for MCUs and embedded platforms
in general. I suspect that this is only a matter of time because of the
growing attraction to PyTorch, especially among academic and research users.
According to statistics1, PyTorch’s dominance is strongest
at vision and language conferences (outnumbering TensorFlow by 2:1 and 3:1
respectively), and PyTorch has also become more popular than TensorFlow at
general machine learning conferences like
ICLR
and
ICML. Eventually some of these researchers will migrate into the industrial space
and adapt PyTorch for the edge computing environment.
To specifically address the question of PyTorch as a good choice for MCUs,
since it can generate ONNX models which can be compiled by Glow, processing
platform restrictions are minimal. And with Glow as an extension of PyTorch,
it will be even easier to generate bundles. The user can generate bundles
directly from the Python script, without having to first generate ONNX models.
Soon, NXP will release an application note that provides guidance to create
and deploy a model using PyTorch and Glow.
We’ve recently rolled out our official support for Glow. In fact,
it’s tightly integrated into our MCUXpresso SDK with several project
examples. We’ve also packaged the Glow compile and quantization tools
into an easy-to-use installer with detailed documentation and labs to help you
get up and running quickly with your own models. With such significant
performance and memory benefits, this compiler will be a great boon for
embedded system developers deploying machine learning with the i.MX RT series
of crossover MCUs from NXP.
Want to Learn More?
Read the
press release
Explore our eIQ® Machine Learning software development
environment
Visit
Pytorch
1 Visit
The Gradient




